At Transnovasi, one of our users’ favorite features is viewing historical data collected at least a day before opening the application. However, this data is massive, approximately 250-300MB in size. Consequently, users had to wait for some time (typically up to 1 minute, depending on their internet speed) for the data to be fetched and displayed by the application.
Our first UX improvement was adding a loading indicator to inform users about the data download status. But this wasn’t enough. It would be frustrating for users to download at least 250MB every time they opened that page.
After brainstorming with our frontend web team (Arga and Adit, our rockstar frontend developers), we agreed to try a caching solution using IndexedDB. This initiative effectively eliminated user wait time for those who had previously downloaded the data.
In this post, I’ll share what we implemented, how this initiative helped improve the user experience, and its business impact.
Of course, we can’t make improvements if we don’t understand what’s wrong with our current implementation.
The data sent by the server roughly looks like this:
type HistoricalData = {
timestamp: string;
id: string;
content: string;
};
type HttpResponseBody = Array<HistoricalData>;
The array of historical data is ordered ascending by timestamp. This historical data is static — in other words, once stored, it won’t change.
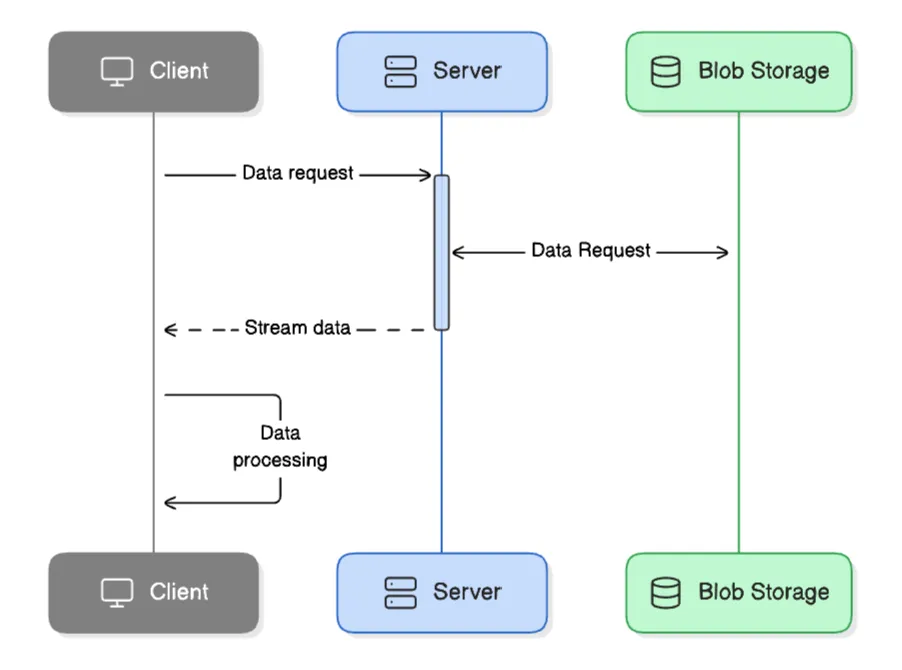
At minimum, this sequence diagram illustrates how the historical data is sent to the client:
In a real-world case we encountered, the downloaded data size was 407MB with a download time of 1.6 minutes (mindblowing!)

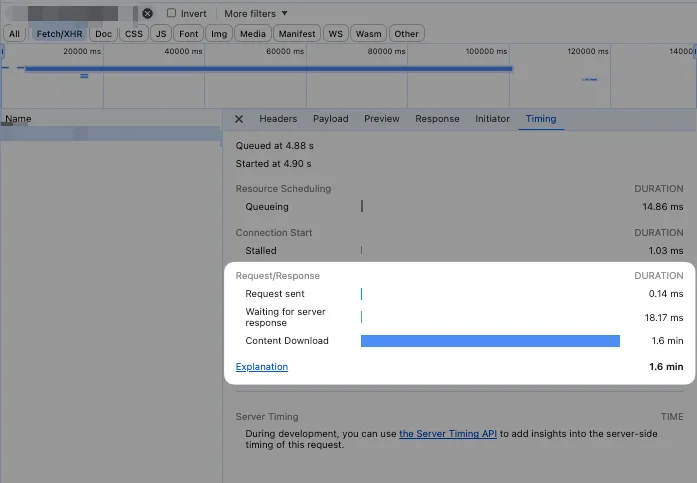
According to our metrics, this feature is one of our most frequently used features. Imagine how frustrated users must be when they have to wait 1.6 minutes and download 407MB of data every time they use this feature. Note that 407MB is for just one dataset.
At that time, we considered several potential solutions:
First solution candidate: What if we limited the downloadable data and implemented pagination? Turns out, this approach wasn’t feasible because splitting the data into smaller chunks would cause users to lose critical information.
Second approach: Have users download the data first as a file, then open it independently using their browser. This approach could significantly reduce network calls since users would only need to request data once — when the page first loads. However, while this approach could address the network call issue, it would be extremely inconvenient for users.
The second approach led us to consider caching — storing files temporarily somewhere for easier access. Based on this solution, we explored several data storage mechanisms available in browsers:
We quickly ruled out session storage and local storage for these reasons:
Our remaining options were Cache Storage and IndexedDB. Since we weren’t familiar with either solution, we evaluated them based on these criteria:
After a brief research, we found that Cache Storage stores data based on sent request objects, as shown in the examples on MDN. Given our limited decision-making timeframe, we chose IndexedDB.
We found several advantages with IndexedDB:
localStorageTo simplify our use of IndexedDB, we used a wrapper called Dexie.js. We created a class to handle storing data in IndexedDB:
export class HistoricalDataIDB extends Dexie {
// Stored data
historicalData!: Table<{
id: string;
internal_id: string;
date: string;
data: Array<HistoricalData>;
}>;
constructor() {
this.version(1).stores({
historicalData: "++id, [internal_id+date]",
});
}
}
In the class above, we set up a class that will interact with IndexedDB. The following line in the constructor:
this.version(1).stores({
historicalData: "++id, [internal_id+date]",
});
Here, we don’t want to include “data” as part of the index, so it’s not included in the schema definition. Dexie.js has a very straightforward cheatsheet page that I highly recommend reading!
After creating this class, all we need to do is add code to check whether the desired data already exists. Our implementation looks something like this:
type HistoricalDataRequestParams = {
date: string; // "yyyy-MM-dd" format
internal_id: string;
};
async function getHistoricalData(params: HistoricalDataRequestParams) {
const historicalDataIDB = new HistoricalDataIDB();
// Check if historical data already exists
const cachedHistoricalData = await historicalDataIDB.historicalData.get({
internal_id: params.internal_id,
date: params.date,
});
if (cachedHistoricalData) {
return cachedHistoricalData.data;
}
return axios
.get("/historical-data-url", {
// params
})
.then((res) => {
// client side validation goes here...
// store data in indexed db
historicalDataIDB.historicalData.add({
internal_id: params.internal_id,
date: params.date,
data: res.data,
});
return res.data;
});
}
Before sending a request, we check whether the desired data already exists in IndexedDB. We can query data based on the combination of internal_id and date, as defined in our class schema above.
If the data exists, we simply return it. If not, we request the data from the server. After validation, we store the data in IndexedDB and then return it.
This sequence diagram illustrates the improvement after we use IndexedDB:
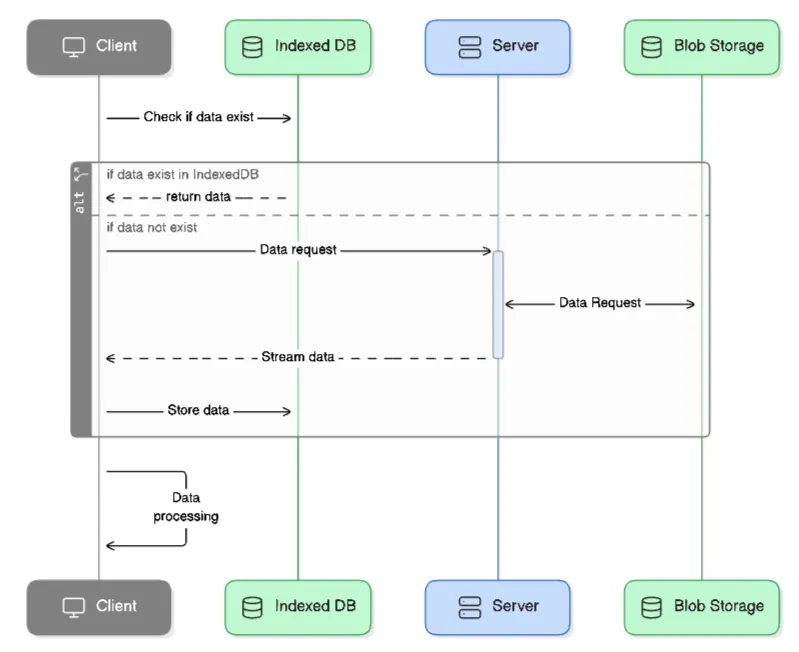
After implementing this improvement, users experienced a significant impact on load times after the initial page load. While users still need to download the data the first time, they don’t have to download it again on subsequent visits.
Throughout this improvement process, we learned several key lessons.
First, we discovered there are many client-side storage solutions available. By understanding the characteristics, advantages, and disadvantages of each solution, we can choose the most appropriate one for our problem. In our case, we had two viable solution candidates: CacheStorage and IndexedDB.
Second, making quick decisions while weighing the pros and cons of each solution candidate proved successful. We realized we would often face similar situations in the future. The ability to learn and take calculated risks significantly determines what can be achieved in a short timeframe.
Finally, by prioritizing user needs and remaining open to feedback, we can help users achieve their goals. In this case, our team wanted to improve the user experience of our application. Based on this, we concluded that client-side data caching was the solution (at that time), and this solution paid off.
If we face a similar situation in the future with more time to think and test solution candidates, we might consider addressing these questions:
In this article, I’ve walked you through how we leveraged IndexedDB to implement client-side caching for large static data.
Special thanks to our TBP frontend web team members, Arga and Adit, for their contributions to this rapid research initiative.
I hope you found these insights valuable for your own projects!